Appearance
Q:如何使用 RAG ?
1、基于开源知识库平台快速使用RAG(Dify、FastGPT 等)
2、基于LLM应用框架来上手RAG(OpenAI SDK、Langchain、LlamaIndex、Vercel AI SDK)
我们选择 Dify 来使用 RAG,本节课(RAG 知识库数据准备):
如何准备私有组件库的 RAG 知识库数据
实际操作案例
如何准备私有组件库的 RAG 知识库数据
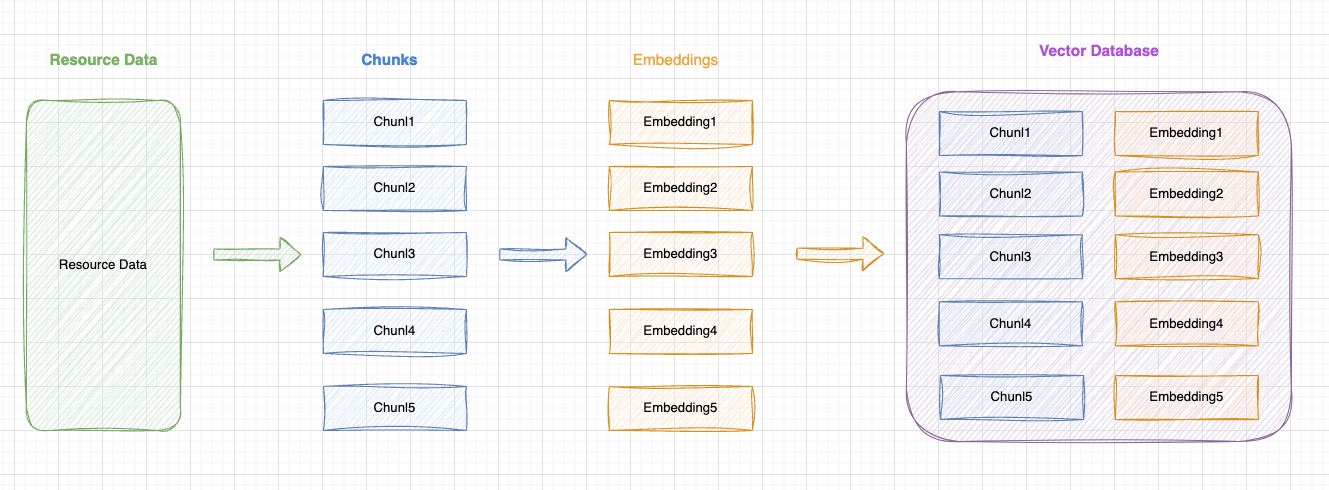

有 2 个关键的点:
组件 Chunk 知识的
完整性保证chunk 包含的组件的语义和功能是
清晰的(因为向量的检索是根据语义相似度来检索的)
为了保证上述两点,我们开始准备私有组件库数据:
组件 Chunk 知识完整性保证:
将单个私有组件的知识库数据放在单独的 md 文件中保存,每个 md 文件内容就是单个的 Chunk,如下:
md
table.md
<!-- 这里是Table组件的知识库数据 -->md
input.md
<!-- 这里是Input组件的知识库数据 -->Chunk 包含的组件的语义和功能清晰性保证:
在知识库数据中,可以包含组件的功能描述、使用场景、props类型定义、代码示例等信息。
Q: 直接把组件的完整代码放进去是否可以?
A:不建议,全量代码占用的上下文太多,尽管现阶段的 AI 已经支持了超大的长下文 Context,但是随着 Context 的长度越大,AI 的推理能力也会下降,容易抓不到问题的
重点。
在这里,我将:使用场景、组件的API放入知识库数据中,示例如下:
md
# Table
## How To Use(使用场景)
Table 组件用于展示数据,通常用于展示列表数据。
## API(组件的 API)
- data: Array<{ name: string, age: number }>
- columns: Array<{ title: string, dataIndex: string }>可以参考 Antd 的组件库文档编写规范,基本上直接可以拿过来作为 RAG 的知识库数据。
实际操作案例
- Clone 私有组件库的 Repo 到本地,安装相关依赖。
bash
git clone https://github.com/AI-FE/private-bizcomponent-website.git
pnpm install- 将私有组件数据转换为适合 Dify 的知识库数据格式。
bash
cd packages/@private-basic-components
node ai-docs/format-docs.js在这个脚本中,会遍历/components目录下的所有组件文档,从文档中收集组件的使用场景、props api 类型定义作为知识库的原始数据。
脚本执行完成之后,会在ai-docs目录下生成一个basic-components.txt文件。
在
basic-components.txt中,包含-------split line-------,这个是用来后续将组件的知识库数据切分到不同的 Chunk 中,保证每个 Chunk 中的组件知识是完整的。
在
basic-components.txt中,包含<when-to-use>和<API>标签,这个用来保证当前组件语义和功能是清晰的。
作业
将上面的 basic-components.txt 知识导入到 Dify 中,并创建知识库,并在 Dify 上创建一个引用该知识库的 RAG 应用。
支持:基于private-basic-components私有组件库生成业务组件。