Appearance
前面的课程:基于开源组件库生成业务组件
Q:如何基于公司私有组件库生成业务组件?
本节课:
三种解决方案(包括预训练自有模型、Fine-tuning、RAG)
RAG 详解
- 前置名词
- 图示构建 RAG 向量知识库的过程
- RAG 向量检索过程的简单示例
- RAG 方案拓展
- 如何使用 RAG?
三种解决方案
Q:为什么大模型不能直接生成基于公司私有组件库的代码?
这个问题的本质是:由于大模型的训练数据集不包含你公司的私有组件数据,因此不能够生成符合公司私有组件库的代码。
因此,解决问题的核心就是:让大模型知道你公司的私有组件库是什么样的。
预训练
预训练是整个大模型训练过程中最复杂的阶段,如 GPT4 的预训练由大量的算力(GPU)在海量无标记的数据上训练数月,最终产出基座模型。
海量无标记数据:
包含:互联网上的公开数据(开源组件库)
不包含:公司私有组件库
尝试让公司私有组件库数据包含在预训练的海量无标记数据中(相当于让学生在长期学习中,加入公司私有组件库的知识):
从 0 ~ 1 ,预训练一个属于你自己的基座模型(自定义训练数据集)
考虑将公司的私有组件库
开源,暴露到外部海量无标记数据中
Fine-tuning(微调)
基于基座模型,使用少量已标记的数据(相对预训练来说)进行再训练,让模型更符合你的特定场景。
RAG:Retrieval(检索)- Augmented(增强)- Generation(生成)
本质:一种思想和方法论,目的是为了解决大模型在特定场景(如公司私有组件库)的"幻觉"问题。

从大模型外的知识库(如私有的向量数据库、联网的实时数据等)中检索与查询相关的信息
结合检索出的信息以及原始查询组合为新的查询,一起给到大语言模型
由于检索出的信息包含在查询的上下文中,所以生成包含专业领域(大模型外的知识)的内容。
方案对比
优、缺点
| 方案 | 优点 | 缺点 |
|---|---|---|
| 预训练 | • 效果相对最好,模型能完全理解私有组件 | • 成本极高(算力、时间、人力) • 技术门槛高 • 需要海量训练数据 • 维护成本高 |
| Fine-tuning | • 成本相对较低 • 只需少量标注数据(相对预训练来说) • 可以快速适应特定场景 | • 效果不如预训练 • 可能出现灾难性遗忘 • 仍需要一定的算力和专业知识 |
| RAG | • 实现简单,成本最低 • 无需训练,可即时更新知识 • 可控性强,易于维护 • 可以保证知识的准确性 | • 受限于上下文窗口大小 • 检索质量依赖于向量化效果 • 响应速度可能较慢 |
使用场景
| 方案 | 适用场景 |
|---|---|
| 预训练 | • 大型科技公司有充足资源 • 需要构建完全定制化的模型 • 有海量专有数据需要学习 • 对模型理解深度要求极高 |
| Fine-tuning | • 有特定垂直领域的应用需求 • 有一定的标注数据集 • 需要模型具备特定的能力 • 预算和资源相对充足 |
| RAG | • 快速落地 AI 应用 • 需要及时更新知识库 • 对知识准确性要求高 • 资源有限但需要快速实现 |
选择路径
RAG > fine-tuning(微调) > 预训练
最终选择
RAG
RAG 详解

前置名词
Chunk: 将文本(或其它数据)切分为每一段数据,是一种数据切片的方法。Embedding: 将每个 chunk 转换为向量,是一种将高维空间的数据(文字、图片等)转换为低维空间的表示方法,后续可以通过匹配向量之间的余弦相似度来实现语义检索。Vector Database: 向量数据库,用于存储 Embedding 和原始 Chunk 的数据库(注意:某些 Vector Database 只支持存储 Embedding,需要自行来建立 Embedding 和原始 Chunk 之间的映射关系)。
图示构建 RAG 向量知识库的过程
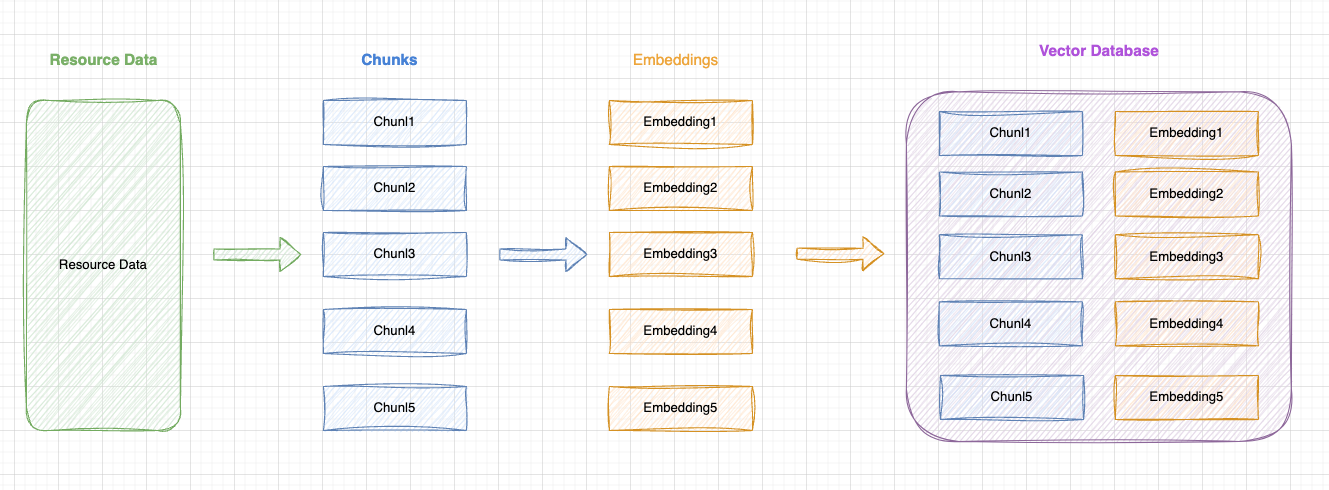
原始数据(Resource Data):
- 从各种来源收集原始数据,比如公司私有组件库的文档文本。
分块(Chunking):
- 将资源数据细分为更小的块,称为
Chunk。
- 将资源数据细分为更小的块,称为
向量化(Embedding):
- 将每个
Chunk转换为向量表示,便于后续根据向量进行语义相似度匹配。
- 将每个
存储至向量数据库:
- 将所有的
Chunk和Embedding一一对应存储在向量数据库中,用于后续向量匹配检索出原始的 Chunk 数据。
- 将所有的
RAG 向量检索过程的简单示例

用户输入一个问题,如:
帮我生成一个table,包含姓名、年龄、性别。将问题转换为向量表示。
将用户需求的向量和向量数据库中的向量进行相似度匹配,检索出相似度高的数据源(Retrieval)。
将检索出的数据源和用户需求的问题组合(Augmented),一起输入给大模型(Generation)。
RAG 方案拓展
朴素 RAG
高级 RAG
关键优化点:
检索前优化:
- Query Routing(路由):根据用户需求选择合适的检索方式
- Query Rewriting(重写):根据用户需求重写查询语句
- Query Expansion(扩展):根据用户需求扩展查询语句
检索后优化:
- Reranking(重排序):根据用户需求重排序检索结果
- Summary(总结):根据用户需求总结检索结果
- Fusion(融合):根据用户需求融合检索结果
模块化 RAG
模块化 RAG 将系统拆分为独立可替换的功能模块:
CRAG(Corrective Retrieval Augmented Generation)
CRAG 的关键优化点:
评估器模块(Evaluator):
- 对检索结果进行质量评估
- 将知识分类为:相关知识、存疑知识、不相关知识
- 通过评估确保输入到大模型的知识质量
- 减少"幻觉"的产生,提高答案准确性
- 作为知识分流的决策点,确定后续处理路径
问题重写模块(Query Rewriter):
- 针对存疑/不相关知识进行问题重写
- 优化查询表达,提高检索准确度
- 通过重写扩展问题维度,获取更多相关上下文
- 实现查询的自我纠正和优化
- 作为知识补充的入口,提供二次检索机会
重检索模块(Re-Searcher):
- 执行重写后问题的二次检索
- 补充和扩展知识库的查询范围
- 提供多轮检索的可能性
- 与原始检索形成互补,提高召回率
- 作为知识获取的最后一环,确保答案的完整性
这种模块化设计的优势:
- 各模块职责明确,可独立优化和替换
- 形成完整的知识评估-重写-检索闭环
- 通过多重保障机制提高最终答案质量
- 灵活应对不同质量的检索结果
- 支持系统的持续优化和迭代
如何使用 RAG?
1、基于开源知识库平台快速使用RAG
Dify
FastGPT
2、基于LLM应用框架来上手RAG
Langchain
LlamaIndex
Vercel AI SDK